At SocketLabs, we lean into a principle made famous by a man named Thomas Jefferson: “Delay is preferable to error.” For ol’ Tom, this philosophy—that wrong decisions are often costlier than delay—was crucial when creating documents like the Declaration of Independence.
Luckily for us, this concept translates brilliantly into the world of email server operations and we lean into this principle with our deliverability operations (DelOps).
The idea of delaying mail isn’t all that novel in the email ecosystem: mailbox providers (MBPs) and anti-spam systems have used delay tactics for decades. Greylisting is a classic example, where the receiving mail server intentionally rejects incoming messages with a temporary error code. Spammers often do not retry, so legitimate senders who do retry end up sailing through. This tactic makes a lot of sense for spam filtering—but why use the “delay is preferable to error” mantra when sending mail?
Resending Messages Isn’t as Easy as it Seems
SocketLabs is an email infrastructure service, so when a message reaches us, in most cases the message was generated through some complicated process by our customer. Reproducing the steps to regenerate a single specific message can be difficult, and it’s even more complex to regenerate large groups of select messages from within a batch.
So, when a mailbox provider has a service outage in which they accidentally reject a randomized subset of messages over the course of a day (like we saw with AT&T a few weeks ago), our customers would struggle to figure out how to resend the mail. In fact, even if we stored the message content for every message for a period, there would be a complex process to identify which messages would need to be re-submitted for delivery.
For this reason, we try not to let email messages fail out of queues if we don’t have to, and instead, we prefer to delay the delivery instead of allowing the messages to fail. Delays allow time for assessment, investigations, and, most importantly, actions.
Delays are a Beneficial Alternative to Failure
An example will help me better explain our rationale.
SMTP as a protocol already has the concept of transient errors built into the standard. So, one would assume this is a solved problem, right? Well…
…Let’s REALLY dive in here. Specifically, we will look into RFC 5321, which defines SMTP.
RFC 5321’s Section 4.2.2 specifies 4XX error codes (e.g., 451 4.3.2 “Please try again later”) imply a transient error. By definition, transient means temporary. So, when encountered, standard practice is to hold the message in a queue and attempt redelivery later because the assumption is the error will be resolved by then.
On the flip side we have 5XX error codes (e.g., 550 5.1.1 “User Unknown”) which imply a permanent error. In these cases, the message is typically logged as a failure right away, with no attempts to retry. No take-backs.
…Except in reality, it is rarely this simple. Consider a few 5XX examples:
- 550 Too many connections from your IP
- 550 5.7.364 Remote server returned invalid or missing PTR (reverse DNS) record for sending domain
- 550 5.7.1 Service unavailable. Please try again later
- 550 permanent failure for one or more recipients (x@x:554 Service unavailable; Client host [outbound-ip122b.ess.barracuda.com] blocked by bl.spamcop.net)
Are these all truly “permanent” errors that should be dropped and not retried? The best answer is every deliverability person’s favorite answer: It depends.
Looking at just an error response code is only one piece of the puzzle. Knowing when in the SMTP transaction an error occurred and having data about other success rates for messages to this destination may help change the answer from “it depends” to something more concrete.
While the SMTP RFCs may not leave much room to interpret how to handle these responses, sometimes it makes more sense to divert from the standards and treat a 5XX as transient if the error might be tied to a temporary error, a DNS glitch, or is simply inconsistent with how it is returned.
This is exactly where our buddy Jefferson’s “delay is preferable to error” shines.
Deep Dive: The AT&T DNS Incident
Now, onto the juicy stuff: On February 20, 2025, around 1:32 AM US Eastern, AT&T started returning an increased number of SMTP errors.
There were three error responses in total:
- 451 4.1.8 Client IP address 142.0.176.0 does not resolve.flpd587.Fix reverse DNS.For more information email [email protected]
- 451 4.1.8 Domain of sender address [email protected] does not resolve
- 550 5.7.1 Connections not accepted from servers without a valid sender domain.flph825 Fix reverse DNS for 142.0.176.0
In analyzing the error patterns, it became clear one of AT&T’s data centers was having trouble resolving DNS records. We could deduce this because the domain att.net and its related consumer mailbox domains (sbcglobal.net, bellsouth.net, etc.) all have four equally preferred MX records:

We could see in our dataset that successful deliveries to two of the four MX records (ff-ip4-mx-vip1.prodigy.net and ff-ip4-mx-vip2.prodigy.net) dropped to 0 exactly when the error responses started occurring.
We could also see each error contains a node identifier such as “flpd587.” All the error responses contained a node starting with “f” and all successful deliveries were accepted by nodes starting with “a,” such as “alph764.”These node identifiers align with the naming conventions of the MX records, and we saw no issues or problems delivering messages to the other two MX values for the AT&T domains.
Not the First AT&T DNS Issue
Two of the error messages returned by AT&T were 4XX (transient, remember) and one error was a 5XX (permanent). Yet here at SocketLabs, we were already treating all three as transient.
Frankly, we’ve been treating this specific AT&T 5XX error as transient since November of 2020. Yes, you read that correctly. Five years ago! In fact, I can find a handful of examples dating back years where confused mail server admins questioned why they were seeing these errors erroneously.
Anyway, since the SocketLabs platform should never be sending mail from IPs or domains without proper DNS records, we are confident in treating these errors as transient as they are only going to occur during outages somewhere in the delivery pipe.
Upon identifying the issue, we didn’t need to make any direct changes to ensure messages would not fail. Talk about being prepared!
However, even if we dropped the ball on preparedness and were not already treating these errors as transient, a simple one-line modification to a configuration file we can deploy across our platform in minutes could have easily been applied.
To be fair, this type of feature really isn’t anything groundbreaking and can be found in many other popular open-source MTA solutions like Postfix. For SocketLabs on-premise MTA customers interested in making similar modifications, our knowledge base article here will walk you through this process: https://help.socketlabs.com/docs/using-the-deliverystatuscodeslist-file [NC1]
The Error is Transient; Now What?
Back to the scenario: Treating the error as transient ensured messages wouldn’t permanently fail or be lost.
However, it didn’t prevent roughly 50% of our SMTP connections from encountering AT&T MX records that were not accepting mail during the outage. As a result, messages remained in the queue awaiting retries, where about half repeatedly encountered the same error.
With escalating retry intervals, some messages became delayed in the queue longer than desirable.
Network Rerouting
Our next step to optimize delivery for customers was to redirect all SMTP connections to AT&T’s functioning infrastructure. This simple configuration change was quickly deployed by our team and successfully eliminated message delays.
By 7:53AM, nearly all messages submitted to SocketLabs destined for AT&T brands were being efficiently delivered in just a few seconds.
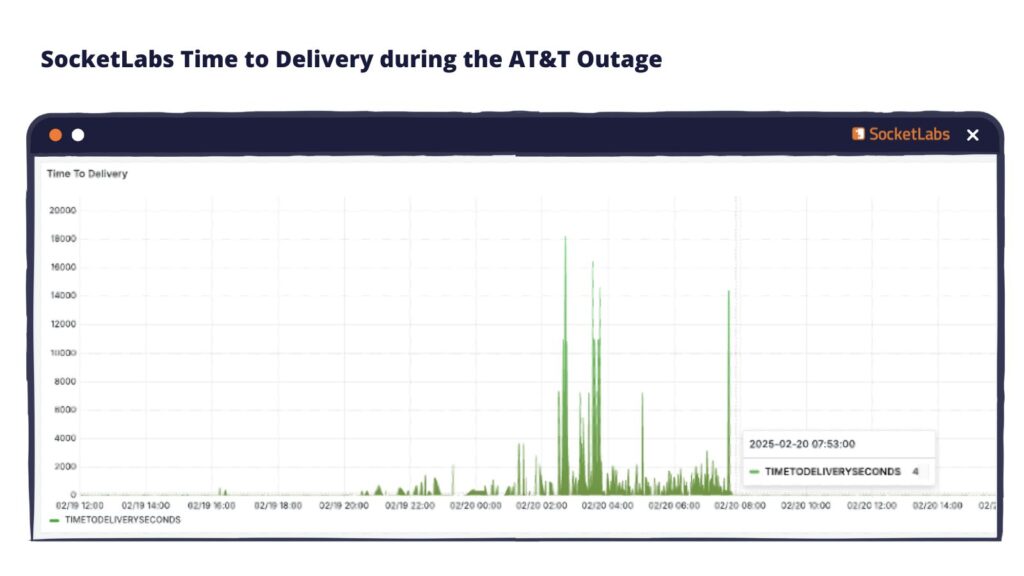
Ultimately, SocketLabs customers experienced a 99.2% successful message acceptance rate with AT&T on February 20th. Given AT&T did not fully resolve their issue until approximately 19 hours after it began, our proactive measures significantly reduced the potential impact on message traffic throughout the day.
Good job, team! We did it.
…But, did everyone do it? Unfortunately not.
Why Proactive Email Infrastructure Management Matters for Email Deliverability
Email is a sprawling ecosystem composed of interdependent systems, each returning unique signals or errors. Clearly, relying solely on rigid 4XX versus 5XX logic risks losing valid messages due to misconfigurations or network issues beyond your control.
Active network management and responsiveness to industry issues, such as mailbox provider outages, might seem obvious—something all major email infrastructure services should handle. We believe it’s a reasonable expectation for providers in this space to proactively manage and optimize their MTAs. Unfortunately, it seems this is not the norm.
Using data from SocketLabs Spotlight—our email analytics tool designed to extract insights from email streams sent through various infrastructure vendors—we’ve observed not all vendors follow through on their commitments.
In fact, despite bold claims such as, “Getting your emails delivered to the inbox is our #1 priority,” some of the largest providers did not meet expectations.
Specifically, our data from February 20 revealed only 55% of messages submitted to a popular, top email vendor were successfully delivered. This suggests this provider may have historically overlooked such errors, and during this 19-hour incident, they failed to adequately optimize message processing for their customers.
They weren’t alone, either.
Our data shows another large email infrastructure vendor who bills themselves as the “top-notch email sending service” were only able to achieve 80% delivery rates to AT&T through the incident. While 80% is significantly better than 55%, it’s still 20% of mail not being delivered to its destination.

I’d be hard pressed to find a sender who would be happy with that figure. Particularly when our delivery rate during this period was 99.2%.
The Future of Delays and DelOps
Our real-time insights into our messaging queues play a crucial role in applying our mantra, “Delay is preferable to error,” effectively helping us avoid errors and ensure reliable delivery for our customers through a proactive approach.
We’ve also got new features coming soon on our product roadmap, aimed at significantly enhancing customer insights into delivery delays, transient errors, and the full lifecycle of each message.
At the end of the day, the primary goal of these enhancements is to empower customers with self-service tools to quickly understand “Why did this message get delayed?”
We prioritize improving customer insight and visibility because your choice of email infrastructure vendor significantly impacts your overall success. While incidents like the recent one involving AT&T are thankfully rare, how a vendor manages these situations speaks volumes about their reliability and commitment to email.
At SocketLabs, we believe the optimal approach to email deliverability involves proactive management, guided by real-world expertise and adaptable decision-making. In this truly wild world we live in today, choosing deliberate delay over irreversible error usually proves to be a sensible strategy.
How does your vendor approach these challenges?
Have questions about our Deliverability Operations approach? Get in touch! We’d love to discuss handling 4XX versus 5XX codes and share more insights into SocketLabs’ best practices.
Or better yet, sign up for a free trial to see the SocketLabs difference for yourself.